(四)⭐Cache系统
1. 局部性原理
1.1. 时间局部性
- 概念
- 程序中的某条指令一旦执行,则不久以后该指令可能再次执行;
- 如果某数据被访问过,则不久以后该数据可能再次被访问;
- 产生原因:程序中一般存在大量的循环操作;
1.2. 空间局部性
- 概念:若程序访问了某个存储单元,则其附近的存储单元很可能在短时间内被访问;
- 即程序在一段时间内所访问的地址,可能集中在一定的范围之内;
- 典型情况:程序的顺序执行;
2. 高速缓冲存储器 Cache
2.1. 辅存—主存
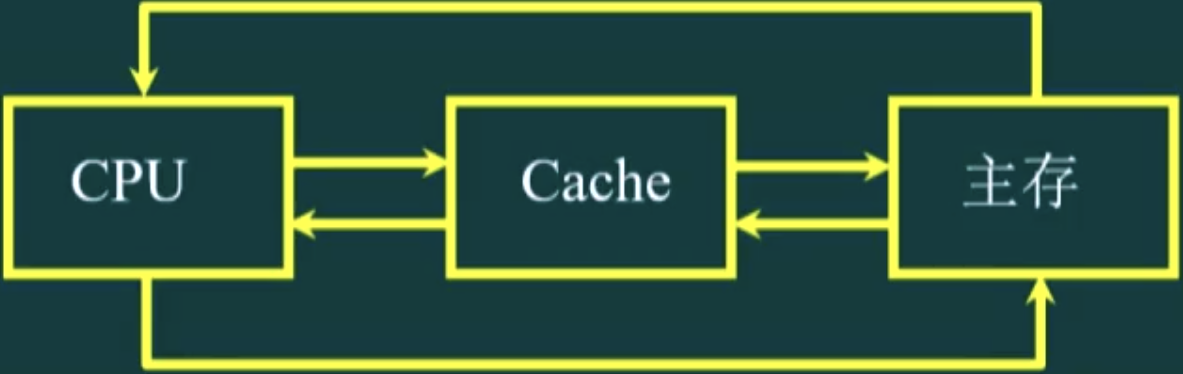
- 根据局部性原理,在 CPU 和主存之间插入一种高速小容量的存储器,称为高速缓冲存储器(cache);
- 作用
- 若当前正在执行的程序和数据存放在 cache 中,程序运行时不必从主存存取数据,转而直接访问 cache;
- cache 存取速度极快,可以提高 CPU 利用率和处理速度;
2.2. Cache 的结构
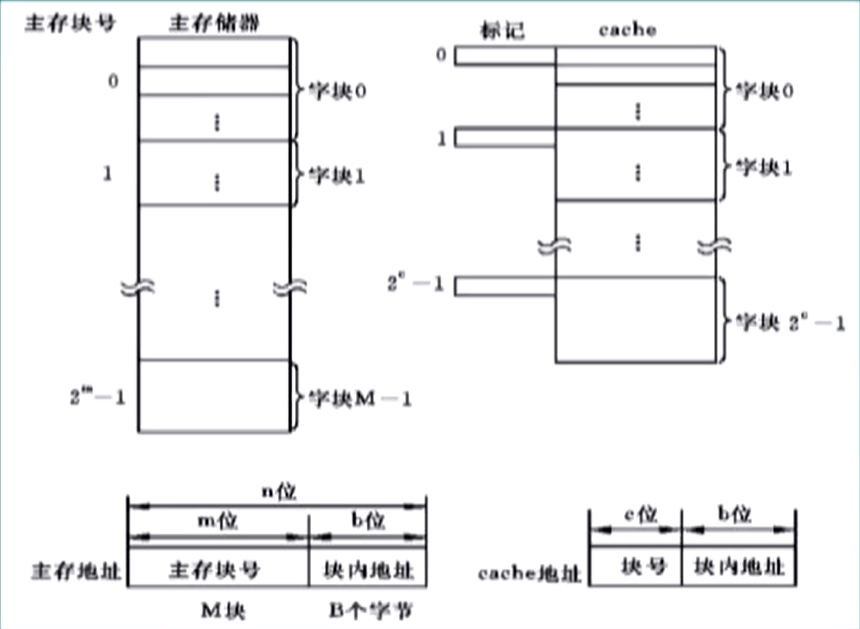
- Cache 和主存都被分为若干个大小相等的块,Cache 的块大小和主存的相同;
- Cache 的容量远小于主存的,因此其块数也远小于主存的;
- Cache 负责保存主存中最活跃的若干块的副本;
- 即:Cache 中的有的数据,主存也一定有,Cache 是一个高速存取副本;
2.3. Cache 和主存的映射方式
- 直接映射
- 主存块号
和 Cache 块号 满足 , 为 Cache 块数; - 主存编号
和 Cache 块号 满足 , 为 Cache 块数, 为块大小; - 地址结构:
主存标记 | Cache 块号 | Cache 块内地址;- 注意:该地址结构位数和主存地址位数相同;
- 优点:直接简单,计算速度快;
- 缺点:不够灵活;
- 主存和 Cache 的块是一一对应,导致很多主存块可能因为一块在 Cache 而不能存进 Cache,同理 Cache 里可能有很多空的;
- 如果 CPU 连续访问对应了同一 Cache 块的主存块,那么就会连续发生替换,降低 Cache 命中率;
- 主存块号
- 全相联映射
- 最灵活但成本最高的映射方式;
- 对主存块和 Cache 块的映射无限制,主存块可以存放在任意 Cache 块上;
- 地址结构:
主存标记 | Cache 块内地址,位数也和主存地址位数相同;- 主存标记:一般就是该块的主存块号;
- 优点:冲突概率低(全装满后才会冲突),Cache 利用率高;
- 缺点:(1) 查找速度慢,(2) Cache 替换操作实现困难;
- 当主存块调入 Cache 时,该块主存标记记录在 Cache 对应块的标记位中;
- CPU 发出访存时,Cache 控制器将块号与每个 Cache 块的标记同时比较,若匹配,则 Cache 命中,否则 miss;
- 同时比较:需要硬件支持(相联存储器);
- 一般用于容量小的 Cache;
- 组相联映射
- 对 Cache 分组,组间直接映射,组内采用全相联映射;
- 地址结构:
主存块号标记 | 组号 | 块内地址; 路组相联:指每组有 块,注意不是一共有 组的意思; - 两种实现方式
- 一、组号
(主存块号 mod Cache 总块数) / 组数(整除); - 是考研的默认映射方法;
- 例:Cache 总块数 4,组数 2,则主存块号为 0, 1, 2, 3 的块,前两块放组 0,后两块放组 1;
- 二、组号
主存块号 mod 组数; - 例:同一,则块 0 和 块 2 放在组 0,块 1 和 块 3 放在组 1;
- 一、组号
2.4. Cache 标记
- Cache 块/行结构:Cache 标记 + 字块;
- Cache 标记:由 4 个部分组成;
- 主存标记:标识主存的块号;
- 有效位:1 位,表示该数据块是否有效;
- 一致性维护位;
- 替换算法位;
- 字块:即数据部分;
- Cache 标记:由 4 个部分组成;
2.5. Cache 查找方式
全相联映射
特点:地址是两段,主存标记 + 块内地址;
- 利用这一点可以快速判断是否为全相联;
查找过程
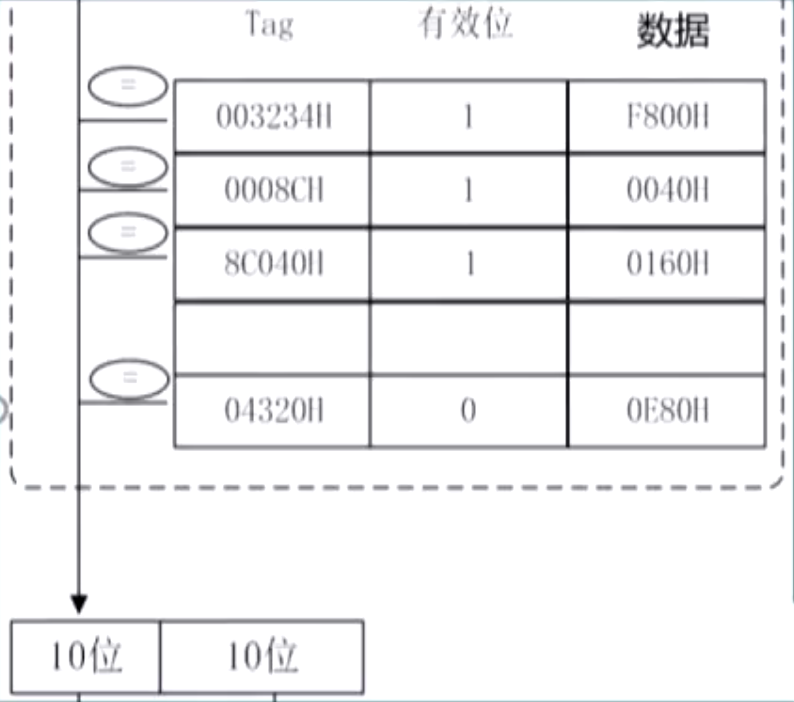
- 用主存地址的主存块号和全部 Cache 块的标记位同时比较;
- 若有相等,则命中,无需再访问主存;
- 否则,Cache miss,此时需要将该块从主存调入 Cache;
直接映射 & 组相联映射
特点:地址是三段,主存块号 + Cache 块号/组号 + 块内地址;
查找过程
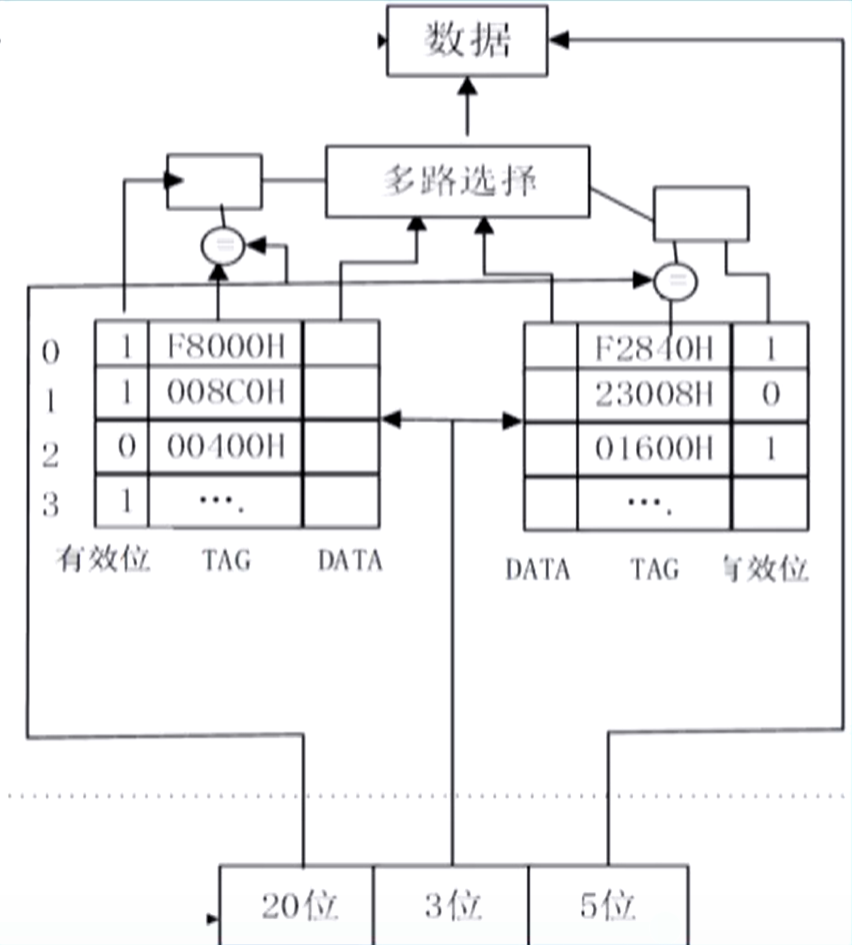
- 首先取地址中间的块号/组号,记为
; - 若
对应一个 Cache 块(Cache 行),则是直接映射,若对应 块,则是 路组相联; - 将主存地址块号和
对应 Cache 块的主存标记对比; - 若有相等,且有效位为 1,则命中;
- 若有相等,但有效位为 0,或没有相等的,则 miss,此时也应将数据调入 Cache;
- 首先取地址中间的块号/组号,记为
注意
- 主存与 Cache 的数据交换(调入)是以块为单位;
- CPU 与 Cache 的数据交换以字为单位;
2.6. Cache 命中率和平均访问时间
- Cache 命中率:
; ,Cache 命中次数, ,Cache 未命中次数;
- Cache 平均访问时间:设
为命中时 Cache 的访问时间, 为 Cache 未命中时访问主存的时间; - CPU 同时访问 Cache 和内存:
; - 默认情况下都是同时访问;
- CPU 仅在未命中时才访问主存:
;
- CPU 同时访问 Cache 和内存:
- Cache 效率:
; - 即 访问 Cache 时间 / Cache 平均访问时间;
- 默认情况同时访问;
3. Cache 替换与写入
3.1. Cache 替换算法
FIFO(First In First Out,先进先出)
总是把一组中最先调入 cache 存储器的字块替换出去;
优点:实现容易,开销小;
不需要实时记录各个字块的情况;
LRU(Least Recently Used,最近最少使用)
把一组中近期最少使用的字块替换出去;
需随时记录 cache 中各个字块的使用情况;
考研中常考;
RAND(随机)
- 不考虑使用情况,在组内随机选择一块来替换;
3.2. 不同映射方法的替换
- 直接映射:不需要替换算法,每个主存块对应的 Cache 块是唯一的;
- 组相联映射
- 主要使用 LRU 算法(in 考研);
- 替换算法位数:
, 为每组块数(N 路组相联);
- 全相联映射
- 替换算法位数:
, 为 Cache 总块数;
- 替换算法位数:
3.3. Cache 写入策略
- 写入 v.s. 替换
- 写入:可以只更新 Cache 字块中的某一部分;
- 替换:将整个 Cache 字块和主存的某块交换;
- 写回法(Write Back)
- 写入 Cache 时,置位对应标志(一致性维护位),但不更新对应的主存块;
- 被修改字块从 Cache 中替换出来时,再一次性写入主存;
- 又称标志交换法(flag-swap);
- 特点
- 写入次数少;
- 每次写入的量较大(整个块);
- 效率比直写法高一些;
- 直写法(Write Through)
- 写入 Cache 时同时向主存对应位置写入;
- 不需要一致性标志位(脏位);
- 特点
- 写入次数多;
- 每次写入量少;
习题
- 主存 Cache 16 块,采用二路组相联映射。每个主存块大小 32B,按字节编址。主存地址为 129 的单元所在快应装入
- A. 组 0;
- B. 组 1;
- C. 组 4;
- D.组 6;
- 答案:
- 解析:组数
,先算主存块号: (从 0 开始) - 按默认方式映射,组号
,无此选项,所以考虑另一种方式; - 方式二,组号
,选 C;
- 按默认方式映射,组号
- 字长 16 位,主存容量 512K,Cache 容量 4K。设块大小为 4 字,编址方式为按字编址。在下列情况下,分别设计主存的地址格式:(1) 直接映射,(2) 全相联映射,(3) 二路组相联映射,(4) 主存容量变为 512K× 32 位,块大小不变,四路组相联映射
- 解析:除 (4) 外,先计算各种地址位数
- 主存地址位数
,主存块号位数 ; - 块内地址位数
,Cache 块号位数 ; - 1)直接映射,
主存标记 | 块号 | 块内地址,主存标记位数为位; - 2)全相联映射:
主存标记 | 块内地址,主存标记即主存块号,17 位; - 3)二路组相联:
主存标记 | 组号 | 块内地址,组数,组号 9 位,主存标记 位; - 4)四路组相联,组数
,组号 8 位,块内地址还是 2 位。按字编址,字长为 16 位不变,故主存地址总位数应为 位,故主存标记 位;
- 主存地址位数
- 字长 32 位,主存容量 16MB,Cache 容量 8KB,每块为 8 字,按字节编址,现设计一个四路组相联映射 Cache:
- 3.1. 求主存地址格式和各部分的位数;
- 3.2. 设初始 Cache 为空,CPU 依次从主存第 0,1,2,...,99 号单元中读出 100 个字,并重复 10 次,则命中率为?
- 3.3. 若 Cache 访存速度为主存 5 倍,求有无 Cache 情况下,速度提高了多少倍?
- 3.4. 系统的效率为多少?
- 答案:
- 1)格式:
主存标记 | 组号 | 块内地址,位数为 13,6,5; - 2)98.7%;
- 3)提高了约 3.75 倍;
- 4)约 95%;
- 1)格式:
- 解析:
- 1)总位数
,块内地址 位,组数 ,即组号 6 位,主存标记 位; - 2)注意读出的是字 32 位;
- 先计算第
个字对应的主存块号 ,即第 块存放的是第 到 个字(从 0 开始); - 100 个字,块号最大为 12,最后一个块存放 96~99 号字。这 13 个块的组号都为 0;
- Cache 初始为空,则 CPU 调入 Cache 仅在第一轮访问且访问每块第一个字时发生。在此之后,此块已在 Cache 中,访问均命中;
- 由上可知,共有 13 次 miss + 调入,故命中率
;
- 先计算第
- 3)设 Cache 访存时间
则主存为 ,倍数 ,提高了约 3.75 倍; - 4)效率 = Cache 全命中访存时间 / 平均访存时间,
;
- 1)总位数
- 主存地址位数 32 位,按字节编址。设 Cache 中最多存放 128 个主存块,采用四路组相联映射。块大小 64B,每块有 1 位有效位和 1 位脏位用于一次性写回策略。求
- 4.1. 主存地址格式和每部分位数;
- 4.2. Cache 总位数;
- 答案:
- 1)
主存标记 | 组号 | 块内地址,位数为 21,5,6; - 2)68480;
- 1)
- 解析:
- 1)块内地址位数
,组数 ,故组号 5 位; - 2)分析每个 Cache 行/块
- 标记部分:主存标记 21 位,有效位 1 位,脏位 1 位;
- 注意如果没有明确提及替换算法位,就不考虑;
- 对于脏位,只要提及写回法,就默认有 1 位脏位;
- 数据部分:64B = 512 位;
- 标记部分:主存标记 21 位,有效位 1 位,脏位 1 位;
- 共有 128 块,则总位数 128×64×(21+2) = 68480;
- 1)块内地址位数
- 设命中率 95%,Cache 访存速度为主存 5 倍,则采用 Cache 后,存储器性能提高多少?
- 答案:提高了约 3.167 倍(为原来的 4.167 倍);
- 主存地址 32 位,按字节编址。Cache 为直接映射,主存块大小 4 字,字长 32 位,采用写回法。则若 Cache 能存放 4K 字的数据,其位数至少是
- A. 146K
- B. 147K
- C. 148K
- D. 158K
- 答案:C
- 解析:"能存放 4K 字数据"
数据区大小 4K×32 位,即块数 ,然后分析地址格式; - 块号:
位;块内地址: 位;则主存标记为 位; - 分析 Cache 块标记:主存标记 18 位,脏位 1 位,有效位 1 位,共 20 位;
- 故总位数:1024×(4×32+20) = 1024×148 即 148K;
- 块号:
- 指令 Cache 和数据 Cache 分离的主要目的是
- A. 降低 Cache 的缺失损失;
- B. 提高 Cache 的命中率;
- C. 降低 CPU 平均访存时间;
- D. 减少指令流水线资源冲突;
- 答案:D
- 解析:
- 按字编址,Cache 有 4 行,主存块大小 1 字。若初始 Cache 为空,采用二路组相联和 LRU 替换策略,CPU 依次访问主存地址 0, 4, 8, 2, 0, 6, 8, 6, 4, 8,命中次数为
A. 1;
B. 2;
C. 3;
D. 4;
答案:C
解析:首先分析两种组号计算方式(块大小 1 字,且按字编址,因此地址 = 块号)
1)
, 为 Cache 块数, 组数:可得 2, 6 号块为组 1,0, 4, 8 号块为组 0; 2)
, 组数:此时全部块都对应组 0; 方式 1 为默认方式,且若采用方式 2,会导致组 1 无法利用,显然会导致命中率降低,因此此题采用方式 1 计算组号;
使用方式 1,可得每次访问主存块的组号为 0, 0, 0, 1, 0, 1, 0, 1, 0, 0;
采用 LRU 法分析,每组可放 2 个块,√ 表示命中;
块号 0 4 8 2 0 6 8 6 4 8 组号 0 0 0 1 0 1 0 1 0 0 #0 + + 换 0 换 4 √ 换 0 √ #1 + + √ 则命中次数为 3;
此外,若按照方式 2 计算组号,可得命中次数为 1;
- 按字节编址,Cache 分两组,每组 4 块,块大小 512B,主存容量 1MB,则 Cache 用于地址变换表的相联存储器容量为
- A. 4 × 10 bit;
- B. 8 × 10 bit;
- C. 4 × 11 bit;
- D.8 × 11bit;
- 答案:D
- 解析:相联存储器是用于存储 Cache 行/块的标记部分,故计算标记部分大小即可;
- 主存地址 20 位,Cache 组数 2,组号 1 位,块内地址位数 9 位,故主存标记为 10 位;
- 没提到写回方式和替换算法,故不考虑脏位和替换算法位;
- 故标记分大小 8×(10+1) bit,选 D;
- 考虑如下 C 语言程序段,数组 a 为 int,占 4B,Cache 直接映射,数据区大小 1KB,块大小 16B。设执行前 Cache 为空,则此段程序访问数组 a 的 Cache 缺失率约为
cfor (int k = 0; k < 1000; ++k) { a[k] = a[k] + 32; }- A. 1.25%;
- B. 2.5%;
- C. 12.5%;
- D. 25%;
- 答案:
- 解析:关于 Cache 命中的一个结论
- 若每块能存放
个数据,且连续访问 个连续存放的数据,没有循环往复, 能整除 ,则 Cache 不命中率为 ,一般 或 ; :表示在最开始读取数据后又紧接着访问了 次数据。如:计算后重新写回,算 ; - 所以,一般不命中率可记为
或 ;
- 推导
- 因为每块能存放
个数据且连续访问,连续存放,故每 次访问只有最开始的一次未命中,然后 CPU 将该块调入 Cache,之后的访问全部命中,故 ; - 若对于每个数据,读取之后还进行了其他访问的操作,也视为命中,此时不命中率
;
- 因为每块能存放
- 对应到本题,
,直接映射,故可用结论。但是需要注意 ,因为读取 a[k]之后又将其 +32 然后写回,也算一次命中,所以不命中率; - 拓展分析
- 不命中次数:250 次;
- 总访问次数:2000 次;
- 若每块能存放
- 主存容量 32KB,组相联 Cache 容量 2KB,每组 4 块,块大小 64B。设 Cache 开始为空,CPU 从主存单元 0 号开始顺序读取 2176 字节的数据。设 Cache 访存速度为主存 10 倍,采用 LRU 算法,替换耗时忽略不计。求采用 Cache 的加速比;
- 答案:约 8.77;
- 解析:关键在于算出命中率,然后就可根据公式算出加速比;
- 每块大小 64B,能存放
个字节(数据); - 故按照题 10 的公式,不命中率
,命中率 ; - 加速比
; - 注意
- 因为 2176B > Cache 容量 2KB,实际上是会发生替换的;因为题目说明不考虑替换耗时,故可用命中率来直接计算加速比;
- 若循环 10 次这样的访问操作,则不命中率不能按照
来计算,见题 3;
- 每块大小 64B,能存放
- 主存大小 256MB,按字节编址。指令 Cache 和数据 Cache 分离,均有 8 个 Cache 块。块大小 64B,Cache 为直接映射。现有两个功能相同的程序 A 和 B,其伪代码如下所示。设 int 类型为 32 位补码,变量
i, j, sum均分配在寄存器中,数组a按照行优先方式存放,首地址 320,求
c// Program A int a[256][256]; // ... int sum_array1() { int i, j, sum = 0; for (i = 0; i < 256; ++i) { for (j = 0; j < 256; ++j) { sum += a[i][j]; } } return sum; }c// Program B int a[256][256]; // ... int sum_array2() { int i, j, sum = 0; for (j = 0; j < 256; ++j) { for (i = 0; i < 256; ++i) { sum += a[i][j]; } } return sum; }- 12.1. 不考虑一致性算法和替换算法位情况下,Cache 总容量;
- 12.2. 数组元素
a[0][31]和a[1][1]所在主存块对应的 Cache 块号; - 12.3. 程序 A 和 B 访问数组
a的 Cache 命中率为多少?哪段程序更快? - 答案:
- 1)4256 bit;
- 2)#6 和 #5;
- 3)A:93.75%,B:0%;A 更快;
- 解析
- 1)主存地址 28 位,块内地址 6 位,Cache 块号 3 位,故主存标记 19 位;
- 2)数组
a放的是数组 Cache 区,块数 8;a[0][31]地址:320 + 31×4 = 444,主存块号 6;同理得a[1][1]地址 1348,主存块号 21;- 直接映射,主存块号 6 对应 #6,主存块号 21 对应 #5;
- 3)每个块 64B,一个 int 4B,即每个块可存放
个 int; - 对于 A,因为 A 是顺序地址访问,套公式得命中率
; - 对于 B
- 其连续访问的
a[i][j]和a[i+1][j]之间差距 256×4=1024B,块数为 1024/64 = 16; - 由于直接映射,Cache 块号
和主存块号 满足 ,而 ; - 因此,连续访问的数据属于不同主存块,却映射到同一 Cache 块,导致每次访问都会发生替换;
- 因此,B 的命中率为 0%;
- 其连续访问的
- 所以 A 更快;
- 对于 A,因为 A 是顺序地址访问,套公式得命中率
- 主存大小 256MB,按字节编址。指令 Cache 和数据 Cache 分离,均有 8 个 Cache 块。块大小 64B,Cache 为直接映射。现有两个功能相同的程序 A 和 B,其伪代码如下所示。设 int 类型为 32 位补码,变量