(四)指令流水线
1. 指令流水线
1.1. 基本概念
- 流水线技术是一种显著提高指令执行速度与效率的技术;
- 指令流水线:改变各条指令按顺序串行执行的规则,把指令周期划分的更细,使得多条指令的不同指令周期可以在同一时钟周期内并行执行;
- 例:分析,执行指令的两个过程分成取指,译码,执行,访存和写回寄存器四个子过程,并用四个子部件分别处理这四个子过程;
- 可以实现:指令取指完成后,不等该指令执行完毕即可取下一条指令;
1.2. 图解

- 注意:考研特色
- 严谨的说,图中应该是 "每个 机器周期/CPU 周期 执行一条指令";
- 考研为了简化,都假设一个机器周期只包含一个时钟周期,方便理解和计算;
- RISC 借助指令流水线技术,可做到满载时,在一个时钟周期内完成一条指令;
2. 性能指标
2.1. 执行时间
设流水线划分后,平均每段操作需要
的时间; 设每条指令平均分为
段,共有 条指令待执行; 传统串行法:执行时间
; 指令流水线:执行时间
(满载情况); 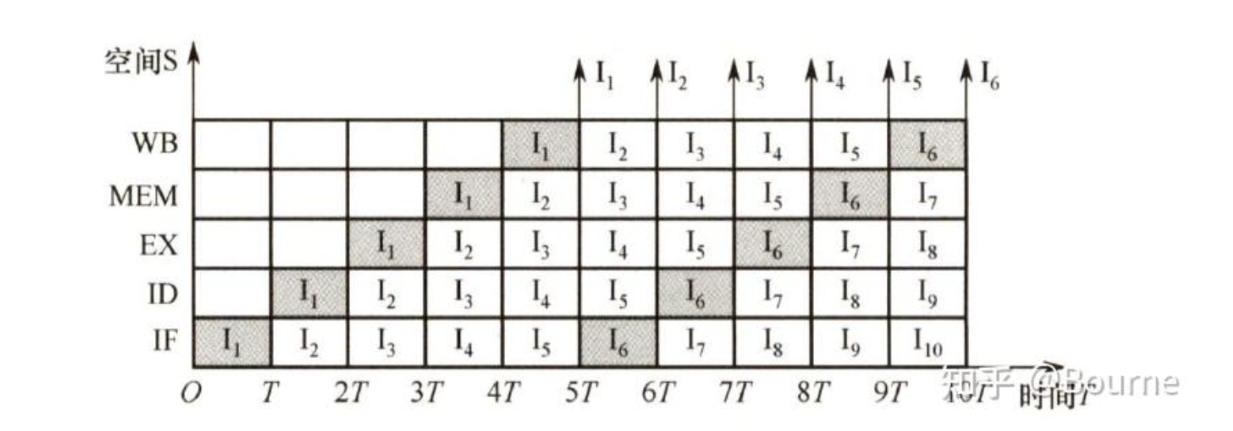
- 图示中,指令从下进入流水线,执行完后从上方出流水线;
- 图示流水线
, ;
2.2. 吞吐率
- 最大吞吐率
: ; - 流水线满载时,
;
- 流水线满载时,
- 实际吞吐率
, 表示连续执行 条指令; - 例:分析 2.1 节图示
- 从 4T 开始流水线满载,此时吞吐率达到最大;
- 若计算从 0 开始到
执行完成(即 10T 时),因为前 4T 流水线不是满载,因此 ,要按照实际吞吐率计算;
2.3. 加速比
定义:
段的流水线与同功能的非流水线处理速度之比; 计算:
表示连续执行 条指令;
2.4. 效率
定义:流水线各段处于工作状态的时空区域 / 流水线各段的总时空区域;
- 即工作面积 / 总面积;
计算:
连续执行 条指令, 流水线分 段;
3. 阻塞因素
- 以下三种 xx 相关也被称为 xx 冒险;
3.1. 结构相关
- 概念:多条指令进入流水线时,硬件资源不能支持指令重叠执行;
- 也称为资源相关因素;
- 例1—同时读写:在某个时刻,重叠执行的两段指令分别为
RegWrite R1和RegRead R1,即同时读写寄存器 R1; - 例2—取数和取指令重叠:数据和指令都存放在主存中,且只有一个访存接口,则重叠执行的取数和取指令操作就会冲突;
- 解决方法
- 等待:前指令访存时,暂停后指令访存一个时钟周期(流水线停顿或空泡),待前指令完成访存;
- 配置额外资源:例 2,配置专门的指令缓存和数据缓存,使得二者分开访问;
- 划分周期:更细地划分时钟周期,如在例 1 中,规定前半部分用于
RegRead,后半用于RegWrite,且 R1 配置独立读写端口;
3.2. 数据相关
概念:某个时刻,某条指令 X 需要指令 Y 产生的数据,而指令 Y 还未执行到位,不能提供数据;
- X 和 Y 先后顺序无关,都有可能产生数据相关冲突;
三种数据相关冲突
- RAW(写后读):连续两条指令 X 和 Y,X 写入寄存器 R,而 Y 读取寄存器 R。Y 在 X 未写入时就完成了读取;
- 导致 Y 读出了错误的旧数据;
- 特点(判断)
- 编号相同:要读写的寄存器编号相同;
- 前后相邻:两条指令执行顺序相邻;
- 前写后读:写指令在前;
- WAW(写后写):连续两条指令 X 和 Y 都要写入寄存器 R,Y 先于 X 写入;
- 导致 X 的写入覆盖了 Y 的写入,从而导致 R 存储了错误的旧数据;
- 特点(判断):编号相同,前后相邻,前写后写;
- WAR(读后写):连续两条指令 X 和 Y,Y 写入先于 X;
- 导致 X 读了错误的新数据;
- 特点(判断):编号相同,前后相邻,前读后写;
- 总结:都可以归纳为,前后按序执行的指令顺序出错;
- RAW(写后读):连续两条指令 X 和 Y,X 写入寄存器 R,而 Y 读取寄存器 R。Y 在 X 未写入时就完成了读取;
按序发射 按序执行:在此架构下,只有可能发生 RAW,而不可能发生 WAW 和 WAR,分析:
按序发射执行的的含义:
- 1)指令流水线被分为取指—取数—运算—写回等阶段,一般来说写回在取数之后;
- 2)按序发射:指令按照严格的先后顺序进入流水线;
- 3)按序执行:指令的执行阶段严格按照先后次序排布,后一指令的阶段不能超过前一条的;
RAW 可能发生:因为写回阶段在取数阶段之后,X 后完成写回和 Y 先完成读取不冲突;
WAW 不可能:因为按序执行,Y 的写回一定发生在 X 之后,所以 WAW 不可能发生;
WAR 不可能:写回阶段在取数之后,且 Y 在 X 之后进入流水线,则 Y 不可能在 X 没完成取数时就完成写回;
若架构不满足按序发射按序执行,则三种冲突都有可能发生;
解决方法
暂停:对产生了数据相关冲突的指令及其后续指令,暂停几个时钟周期,待冲突消失;
软件方法:在 X 和 Y 之间插入数条空指令 NOP,直到 X 完成操作;
- NOP 是一条完整指令,也有取指译码等阶段;
- 非让权阻塞:NOP 在执行时会占用相关寄存器,后续指令不能访问;
硬件阻塞(气泡):在 Y 发生冲突的阶段冻结 Y 及其后续阶段的执行,直到 X 完成操作;
- Y 冻结时,后续指令仍可进入流水线并被执行;
- 若非按序发射按序执行,则后续指令可先于 Y 完成;
- 让权阻塞:Y 被冻结时,后续指令可访问相关寄存器,进行取指译码等操作;
暂停周期数(经验公式):一般暂停
个时钟周期, 为流水线段数;
旁路:设置专用数据通路,让 ALU 直接把 X 的计算结果发给 Y,使得 X 和 Y 不用读写寄存器;
编译优化:编译器动态调整指令顺序,让有可能发生数据冲突的指令不要相邻执行;
3.3. 控制相关
概念:
- 流水线取指需要取 PC 的值,默认情况下顺序执行,取完指 PC 就自增,符合流水线顺序;
- 分支指令或其他可以改变 PC 值的指令,在执行完之前,PC 值不能确定;
- 若下一周期流水线继续取 PC 值然后取指,就有可能出现流程错误;
解决方法
阻塞:阻塞取指阶段的执行,直到分支指令算出结果;
- 无条件直接转移(如
j <target>),其目标地址在取指阶段(操作数)就给出,因此无需阻塞; - 无条件间接转移,一般要在译码阶段完才能取得有效地址,因此流水线阻塞一周期;
- 条件转移指令,则需要阻塞至其 EX (执行) 阶段完成;
- 对于一些简单的条件转移指令(如比较两数相等),可以提前至译码阶段完成,缩短阻塞时间;
- 无条件直接转移(如
延迟转移(编译优化):编译器调整指令顺序,在不改变程序功能的情况下,将一些无关指令插入至阻塞阶段,使得流水线不会空载;
例:xor 指令虽然在 beq 分支指令前,但是可以把它调整到紧接着 beq 之后,填补阻塞;
xor s1, s2, s3 addi t1, t3, 1 subi t2, t4, 2 beq t1, t2, Next ... Next: ...调整后:
addi t1, t3, 1 subi t2, t4, 2 beq t1, t2, Next xor s1, s2, s3 ... Next: ...
分支预测:指在该条分支指令执行完前,就预测其行为(跳转 or 不跳转),然后直接进行对应操作,是一种高效的处理手段;
- 预测错误时:将已经预取和译码的指令无效化,清空流水线,恢复现场,重新进行取指;
- 预测错误的开销较大,约为 10~20 个时钟周期;
分支预测方法:
静态分支预测:每次都预测同一个行为(如不会跳转),在大量分支指令情况下,正确率可接近 50%;
动态分支预测:即根据前一次或前几次的分支预测结果,和当前分的支指令,动态决定预测跳转与否;
实例分析:2 位动态分支预测器
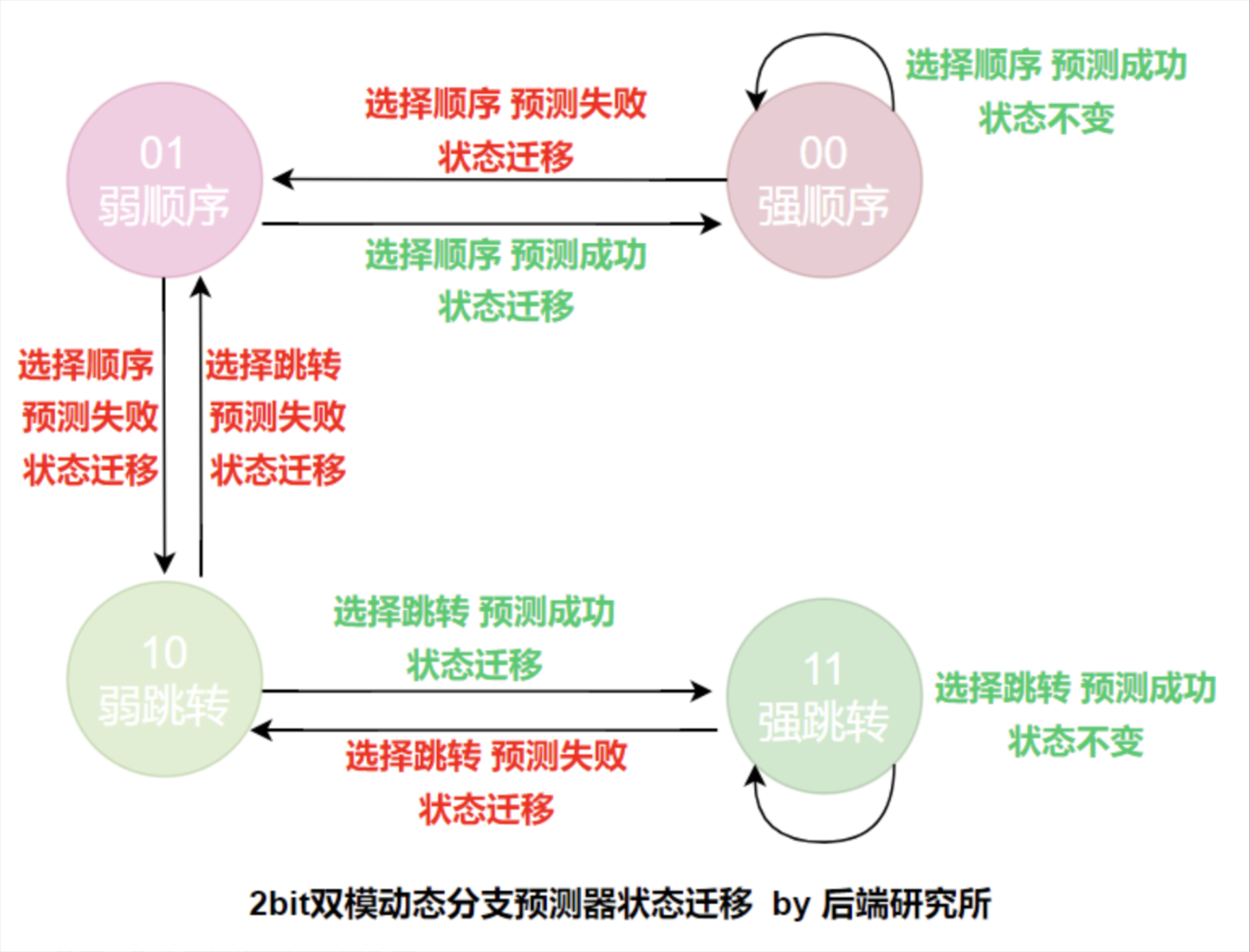
- 采用状态机设计,仅当连续两次分支预测都错,或预测结果反复改变时,才改变下一次的预测;
实际应用中,搭配分支历史表 BHT 和 分支目标缓冲器 BTB 使用;
- BHT:地址—两位状态位,记录每条分支指令的预测状态;
- BTB:对于预测为 "跳转" 的分支指令,缓存其跳转地址;
最坏情况:若一条分支指令的预测结果为 TFTFTF.... (正确和错误之间一直变化),最坏正确率 50%;
实例分析:数组元素的条件求和
cppfor (int i = 0; i < LOOP_COUNT; i++) { for (int j = 0; j < ARRAY_SIZE; j++) { if (data[j] >= ADD_THRESHOLD) { sum += data[j]; } } }ARRAY_SIZE 取 32768,LOOP_COUNT 取
;数组元素均匀随机分布,不超过 256;ADD_THRESHOLD 为128;不启用任何优化 分别在不排序和排序的情况下执行,监测程序性能表现
指标 不排序 排序 用时 (秒) 10.56 3.16 IPC (条/Cycle) 1.04 3.47 分支速度 ( 条/秒) 931.09 3104.68 总分支数 ( 条) 9831.81 9835.40 分支错误数 ( 条) 1140.69 0.3764 分支错误率 (%) 11.60 0.00 排序前:if 分支进入率约 50%,跳转与否排列为 TFTFTF...,为分支预测效率最低的排列,故分支预测错误率较高,程序效率低;
排序后:前一半基本都满足 false,后一半基本都满足 true,因此分支预测错误率可接近 0,流水线满载,效率提高;
优化方法
- 1)排序;
- 2)消除分支:例如把
if语句改为sum += (data[j] >= ADD_THRESHOLD) * data[j](掩模乘法);
同时预取:同时预取跳转与否的指令;
提前分析和判断:例如预取 PSWR 状态字,提前分析指令的结果;
习题
- CPU 主频 1.03 GHz,指令流水线四级,每段需要 1 个时钟周期。现连续执行 100 条指令,没有发生任何阻塞,则吞吐率为
A.
条/秒; B.
条/秒; C.
条/秒; D.
条/秒; 答案:C
解析:套公式,
, , ,则
- 下列三组指令中,可能存在 WAR 冲突的是(M 为主存单元)
选项(M I1 数据流 I2 数据流 A STA M, R2;(R2) -> MAND R2, R4, R5;(R4) + (R5) -> R2B SUB R1, R2, R3;(R2) - (R3) -> R1AND R4, R5, R1;(R5) + (R1) -> R4C MUL R3, R2, R1;(R2) * (R1) -> R3SUB R3, R4, R5;(R4) - (R5) -> R3D ABC 都不对 / / / - 答案:A
- 解析:WAR 读后写,即 X 读 Y 写,Y 先于 X 写入;
- A. I1 将 R2 值存入 M,需要读 R2,I2 会写入 R2,可能发生 WAR;
- B. I1 会写入 R2,I2 会读取 R2,可能发生 RAW;
- C. I1 和 I2 都是写入 R3,可能发生 WAW;
- 因此选 A;
- 五段基本流水线(取指,译码/读寄存器,运算,访存,写回),无转发机制。则下列指令序列存在数据冒险的是
指令 内容 数据流 I1 add R1, R2, R3(R2) + (R3) -> R1I2 add R5, R2, R4(R2) + (R4) -> R5I3 add R4, R5, R3(R5) + (R3) -> R4I4 add R5, R2, R6(R2) + (R6) -> R5- A. I1,I2;
- B. I2,I3;
- C. I2,I4;
- D.I3,I4;
- 答案:B
- 解析:分析题目
- 无转发机制,意味着没有旁路优化,同时如未特别说明,默认是按序发射按序执行;
- 访存阶段是指:若指令需要操作主存,则在此阶段完成。不涉及寄存器操作;
- 首先分析互不干扰指令间的最小距离
: - 本题中,均不访问主存,因此访存阶段不会有任何冲突;
- 本题中 ADD 指令全部是寄存器操作数,在译码时访问寄存器并取数,在写回阶段写入寄存器;
- 故,互相干扰的两个阶段为:#2 译码 和 #5 写回,最小距离为
; 的意义:若一对指令距离超出此值,则可认为不会发生数据冲突,否则可能; - 一般结论:对于
段基本流水线,互不干扰指令的最小距离一般 ;
- A. I1 和 I2 只共享 R2,都是读取而不修改,因此无冲突;
- B. I2 和 I3 共享 R4 和 R5。R5 可能发生 RAW;
- C. I2 和 I4 共享 R2 和 R5。R2 只读不写,R5 只写不读,按序发射执行保证了无干扰;
- D. I3 和 I4 共享 R5,若无按序发射执行,则可能发生 WAR,但题目默认按序,所以无干扰;
- 计算机字长 16 位,补码表示。数据和指令 Cache 分离。表中给出部分指令的格式和功能,其中 M 表示主存单元地址。规定:
指令 格式 功能 加法 ADD R1, R2(R1) + (R2) -> R2算术左移 SHL R12 * (R1) -> R1算术右移 SHR R1(R1) / 2 -> R1取数 LOAD R1, M(M) -> R1存数 STORE R1, M(R1) -> M计算机采用 5 段基本流水线(取指,译码/读寄存器,执行/计算 EA,访存,写回),采用按序发射执行,无转发技术;
同一寄存器的读和写不能在一个时钟周期内进行;
4.1. int 类型变量 x 的值为 -513,存放在寄存器 R1 中,执行指令
SHL R1后,R1 内容为?4.2. 某段时间内,有连续 4 条指令进入流水线,流水线无阻塞,则执行完这 4 条指令需要的时钟周期数为?
4.3. 某高级语言的赋值语句为
x = a + b,三者均为 int 型变量,设此语句被译码为下列机器指令,[x]表示存储单元assemblyLOAD R1, [a]; LOAD R2, [b]; ADD R1, R2; STORE R2, [x];画出该指令序列在流水线中的执行过程;
4.4. 某高级语言中,有一条赋值语句
x = 2*x+a,二者均为 unsigned int 型。只用两个寄存器 R1 和 R2,则执行此语句最少需要多少个时钟周期?画出对应的执行过程图;答案
1)0xFBFE;
2)8;
3)
4)至少 17 个时钟周期;设取指,译码,执行,访存,写回分别用 F, D, X, M, B 表示。指令序列为
assemblyI1: LOAD R1, [x]; I2: LOAD R2, [a]; I3: SHL R1; I4: ADD R1, R2; I5: STA R2, [x];
解析:
1)注意机器字长 16 位,x 也是 16 位的;
2)套公式
, , ; 3)有三次阻塞:
- 第 1 次,数据冲突:I2 和 I3 触发 RAW,I3 需要等到 I2 完成写回才能启动译码(读取操作在译码阶段);
- 第 2 次:按序发射执行,因此 I4 在 I3 卡在取指阶段时不能进入流水线;
- 第 3 次:数据冲突:I3 和 I4 触发 RAW,I4 等到 I3 完成写回后才能译码;
4)没有进行其他优化的条件,故只能手动进行编译优化,即调整指令的顺序,使得流水线效率最高;
调整顺序的原则:
- 可能发生冲突的指令应尽量远离;
- 若冲突已经不可避免,应让冲突发生的时机尽可能晚;
分析指令序列可知,共有如下 5 条指令
assemblyLOAD R1, [x]; LOAD R2, [a]; SHL R1; ADD R1, R2; STA R2, [x];分析约束条件:
SHL R1和LOAD R1, [x]冲突,ADD R1, R2和两条LOAD都冲突,STA R2和ADD冲突;SHL必须排在LOAD R1后,ADD必须排在两个LOAD后,STA必须排在最后;
结合调整顺序的原则可知,上述指令序列已是最优顺序;
画出流程图知,需要至少 17 个时钟周期;