(一)内存管理基础
1. 内存管理的概念
1.1. 可执行存储器
寄存器和主存储器称为可执行存储器;
其访问机制和辅存(即外存,磁盘)的访问机制不同;
CPU 可以在很少的时钟周期内用一条 load 或 store 指令进行访存;
对辅存的访问涉及 IO 设备,中断,驱动程序和物理设备,速度会相差至少 3 个数量级;
1.2. 内存管理
- 主要涉及:逻辑空间和物理地址空间的转换,内存共享,内存保护,内存分配与回收;
2. 连续分配管理方式
2.1. 单一连续分配
用于单道程序环境,内存分为系统区和用户区两部分;
系统区仅由 OS 使用,通常是放在内存的低址部分;
用户区仅供 1 个用户程序使用;
2.2. 固定分区分配
在 2.1 基础上,将用户区划为若干个固定大小的区域;
每个分区只装入一道程序,分区数 = 最大允许并发的数量;
划分分区的方法:
1)分区大小相等:实现简单,但缺乏灵活性,容易造成浪费或程序装不下;
2)分区大小不等:提高了一定的灵活性;
建立分区使用表,标注每个分区的大小,起始地址,分区号,分配状态等信息;
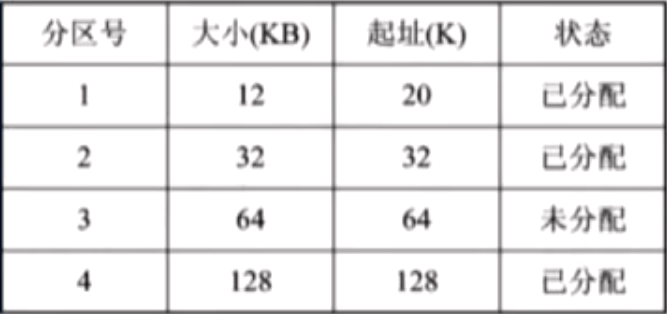
2.3. 动态分区分配
根据进程的需要,动态地分配内存空间,涉及到:分配所使用的数据结构,算法,分配与回收操作;
数据结构
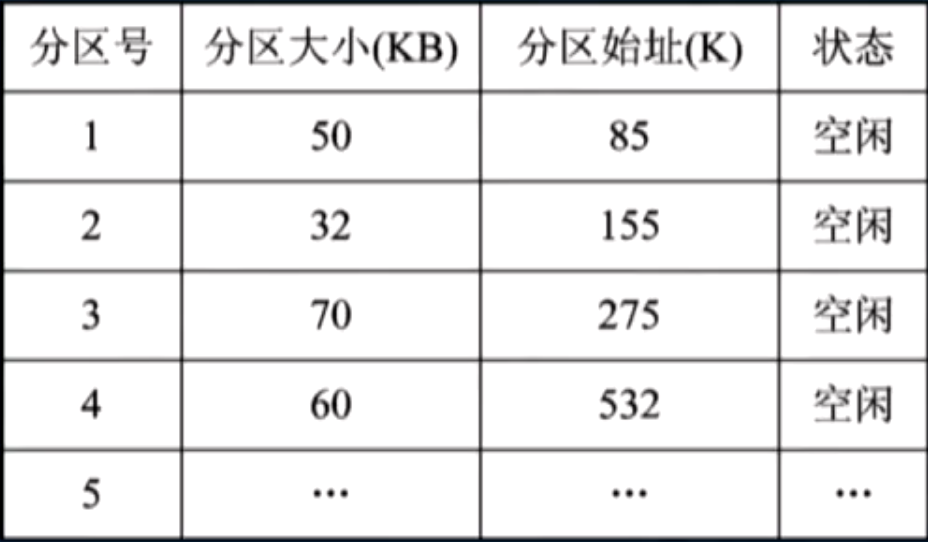
空闲分区表:记录每个空闲分区的分区号,大小和起始地址,本质是顺序表;
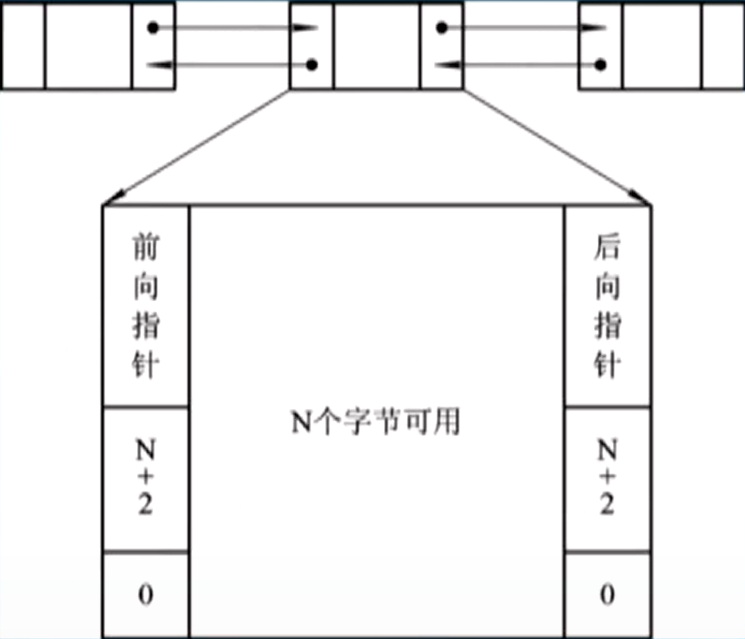
空闲分区链:在每个空闲分区的头部存放分区控制信息和指向前一个空闲分区的指针。在尾部存放指向后一个空闲分区的指针,所有的空闲分区构成双向链表;
分配算法(3. 基于顺序搜索的动态分配算法)
- 是影响系统性能最大的因素;
回收
OS 根据回收区的首地址,从空闲分区链中找到合适的插入点,插入到链表中;
1)若回收区与插入点的前一分区相邻,则不用创建新表项,只需将二者合并,更新新分区的大小;
2)若回收区与插入点的后一分区相邻,同上,此时还要更新新分区的首地址;
3)若回收区和前后两项都相邻,则合并三个,保留前面,取消后面,更新新分区的大小;
4)(不常考)若回收区和前后都不相邻,则创建新项,插入合适位置;
3. 基于顺序搜索的动态分配算法
3.1. 首次适应(First Fit, FF)算法
FF 算法要求空闲分区链按照首地址递增的次序连接;
从链表头开始查找,找到第一个大小能满足要求的空闲分区,从该分区中画出要求的内存空间;
若不能找到,则此次分配失败;
3.2. 循环首次适应算法(Next Fit, NF)算法
在 3.1 的基础上改进:每次不是从链表头开始查找,而是从上一次搜索结果的下一个分区开始;
可以避免低地址空间产生很多小的碎片空闲分区,导致搜索开销增加;
3.3. 最佳适应(Best Fit, BF)算法
BF 算法要求空闲分区链按照容量递增的次序连接;
查找能满足要求,容量又最小的空闲分区进行分配;
3.4. 最坏适应(Worst Fit, WF)算法
和 3.3 相反,查找能满足要求,且容量最大的空闲分区进行分配;
评价 “好坏” 的标准:认为找到一个刚好符合要求的空闲区是 “最好的”,容量越大则越 “坏”;
4. 动态可重定位分区分配方式
连续分配的缺点:随时间推移,OS 会产生很多容量小,不邻接的碎片式分区,此时即使总可用容量足够,也无法将程序装入内存;
紧凑技术:动态移动程序的地址,整合内存碎片,形成整段的大容量空闲分区,需要动态重定位;
动态重定位:程序装入内存后仍是逻辑地址,指令被执行时,才转为物理地址;
为了使得地址的转换不会影响指令的执行速度,需要有硬件的地址变换器支持;
OS 中增设一个 “重定位寄存器”,存放程序的首地址,指令执行时再将首地址和逻辑地址相加;
缺点:移动程序和整合碎片开销较大,实现仍较为复杂;
5. 页式管理
- 允许一个进程被分散的装入到多个不相邻的分区中,称为离散分配方式;
5.1. 页面和物理块
页面:指将一个进程的逻辑地址空间分成若干个大小相等的部分,称为页或页面,并从 0 编号。每一个页的页内地址也是从 0 开始相对编址的;
物理块:将内存按照上述页的大小分成若干个区域,称为物理块(物理页面,页框,帧 frame)并从 0 编号;
为进程分配内存时,以块为单位将进程的若干个页装入对应若干个不相邻的物理块中;
进程的最后一页通常装不满一块,称为 “页内碎片”;
5.2. 页面大小
页面大小选择应适中且是 2 的幂,通常是 512B ~ 8KB;
若页面太大,虽然可以减少页表长度,提高页面交换速度,但是也会使得碎片增大;
若页面太小则反之,此外页表太长也会占用大量内存;
考试时,一般取大小为 1KB,2KB 或 4KB;
5.3. 分页地址结构
以 32 位系统为例;
分页地址结构例子:如图,一个字节,0 ~ 11 位为偏移量,12 ~ 31 位为页号;

- (⭐)从位移量 W 可看出页大小为 4KB,页号 P 可以看出有
个页;
- (⭐)从位移量 W 可看出页大小为 4KB,页号 P 可以看出有
若物理地址为
,页面大小为 ,则页号 和页内地址 为: ; ;
5.4. 页表
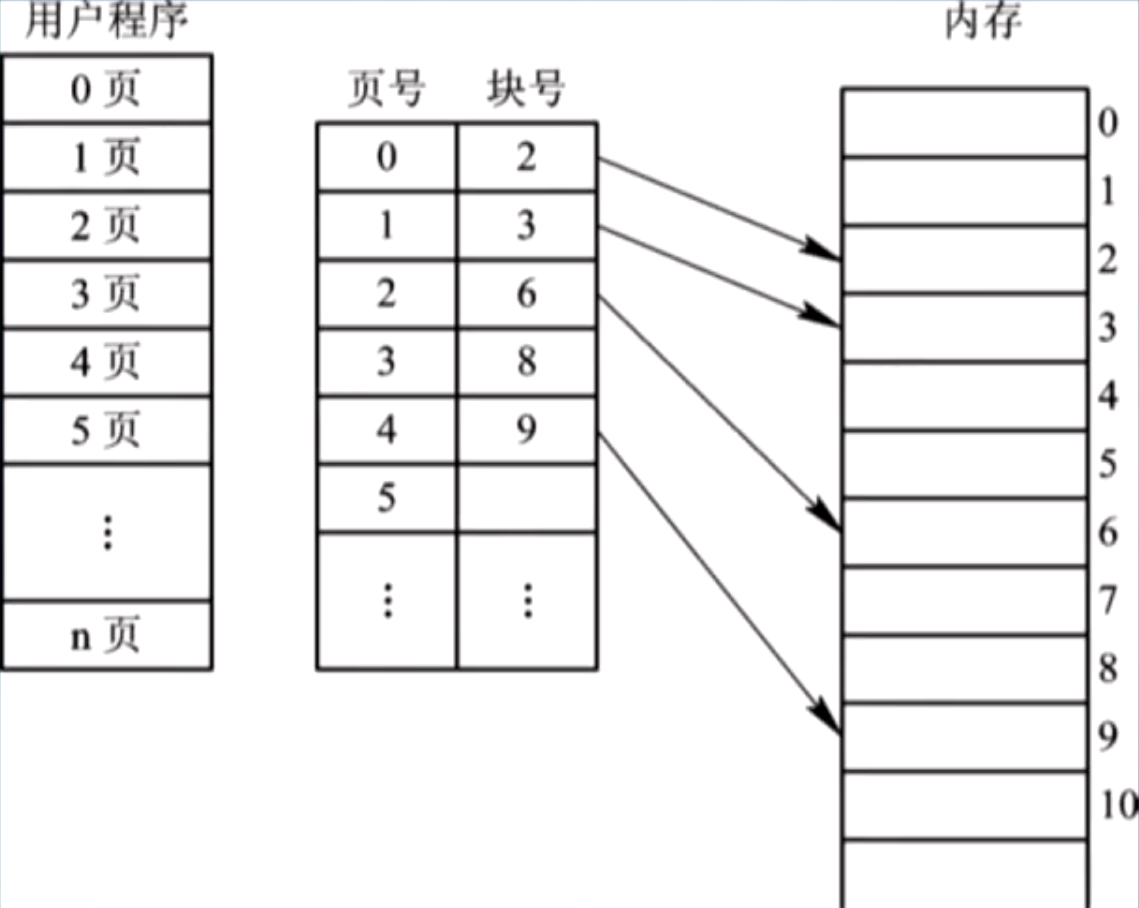
对应页面编号和其物理块得编号,即对应了用户逻辑地址和主存物理地址;
每个进程的页表都不同!
每个项目包含:页号,块号,指向页框的指针,读取控制字段(也成为页描述字);
示意:
6. 地址变换机构
6.1. 基本地址变换机构
页表常驻内存,OS 设置页表寄存器(PTR, Page Table Register),存放页表的首地址和长度;
进程未执行时,将页表的首地址和长度装在 PCB 中。调度到该进程时,才装入 PTR(每个进程的页表都不同!)
分页系统的地址变换机构示意:
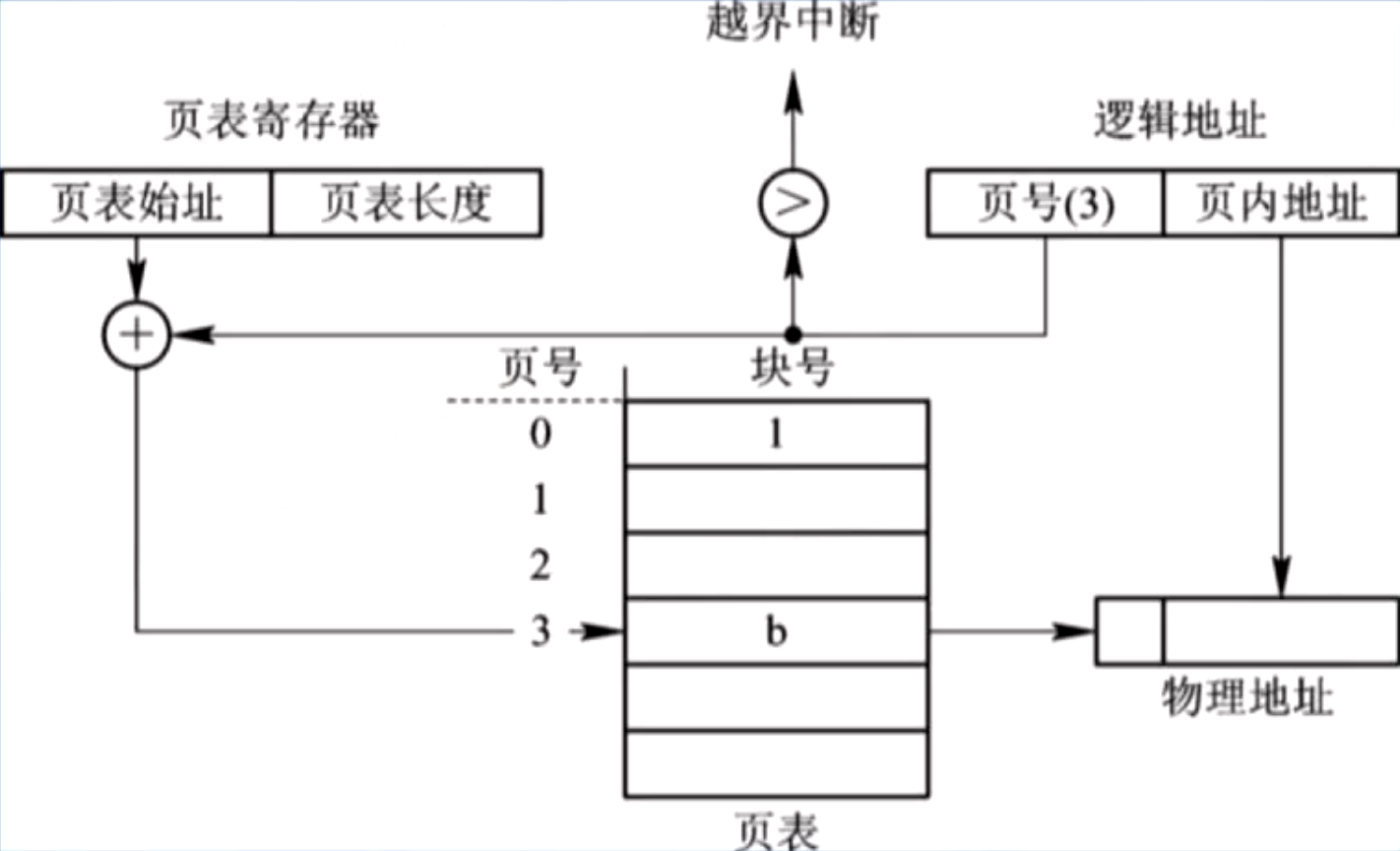
核心部分为页表寄存器 PTR;
注意执行加法之前有越界判断和越界中断机制,避免页号超出页表长度;
6.2. 带快表的地址变换机构
6.1 基本机构的缺点:每次读写数据都要两次访存,第一次访问页表项,第二次才真正访存;
快表:增设一个具有并行查询能力的高速缓冲寄存器(又称联想寄存器,Associcative Memory),用来缓存当前正在访问的那些页表项;
快表通常可存放 16 ~ 512 个表项,设计得当时,命中率可达 90% 以上;
带快表的变换机构示意:
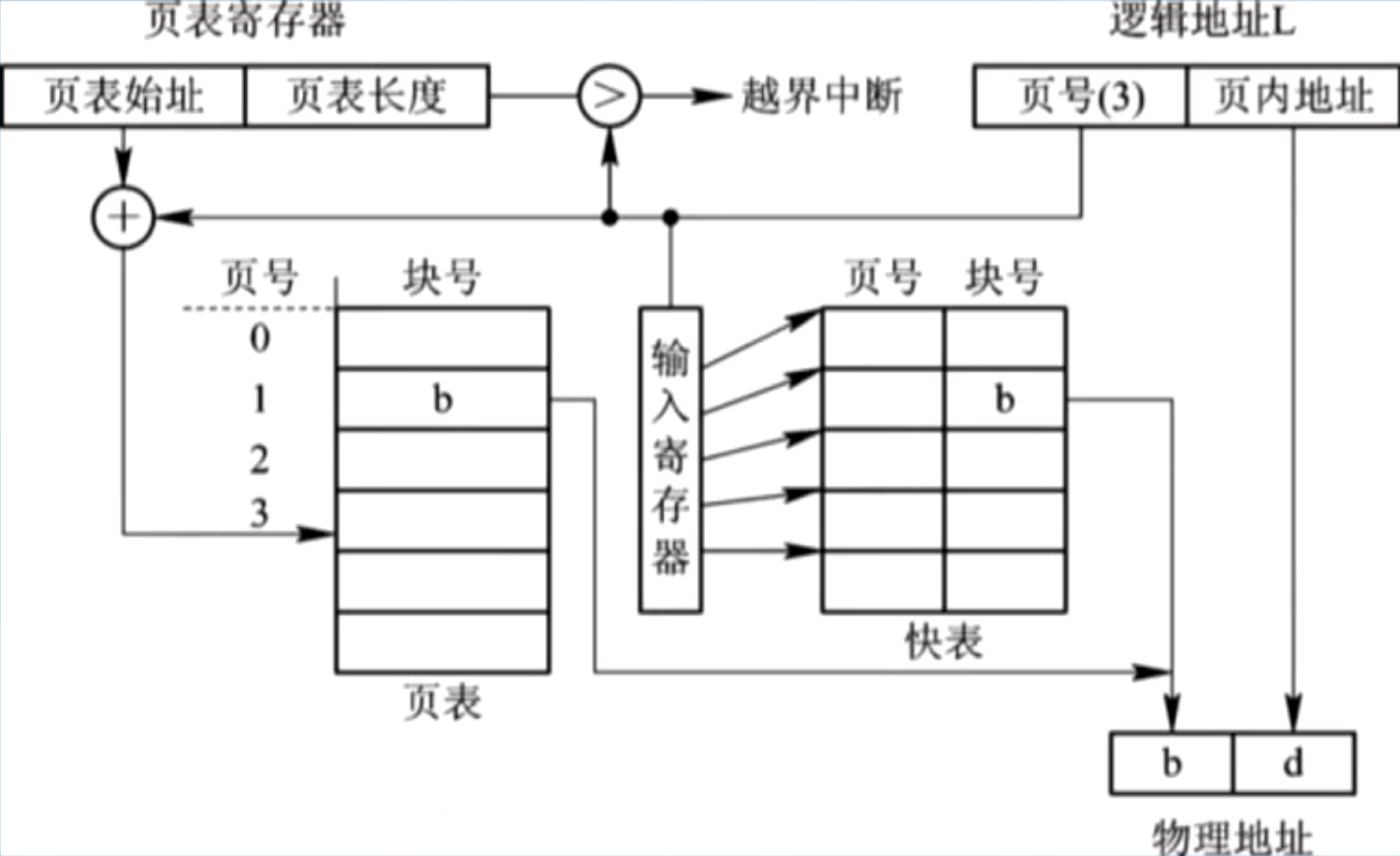
命中:逻辑地址 L
输入寄存器 快表 块号 合成物理地址,访存一次; 未命中:经过页表寄存器先访问页表项,再合成物理地址,访存两次;
内存的有效访问时间(EAT, Effective Access Time)
定义:从内存发出访问请求,到实际访问到内存中的地址单元所需的总时间;
设内存访存一次的时间为
,则普通机构 ,带快表且命中 ;
命中率:在快表中成功查询到所需页表项的比率;
引入命中率后,带快表机构的期望
为: ; 其中
表示命中率, 为访问快表的时间, 是内存访存时间;
7. 两级和多级页表
7.1. 两级页表
定义:将页表按照物理块和页的大小分页(页表的页表),分散在不同的物理块中;
意义:当 OS 内存较大时(如 32 位 4GB),页表本身较大(可达 4MB),还要求连续存放,对于每个进程都要开辟一块连续空间将造成不小的内存管理问题,因此需要将页表也分页管理;
两级页表下,一个逻辑地址示意(32 位 CPU,页面大小为 4KB):

外层页号也称为:页目录号、一级页号
外层页内地址也称为:页号、二级页号
组成部分说明:
页内地址:4KB 对应 Bytes,所以需要 12 bit 来寻址; 外层页内地址:每个页表项为 32 位即 4B,所以有 1K 个页表项,需要 10 bit 寻址; 外层页号:剩下的 bit 全用于外层页号寻址,共 10 bit,即外层页号也是 1K 个页表项;
两级页表的一个地址变换机构图示:
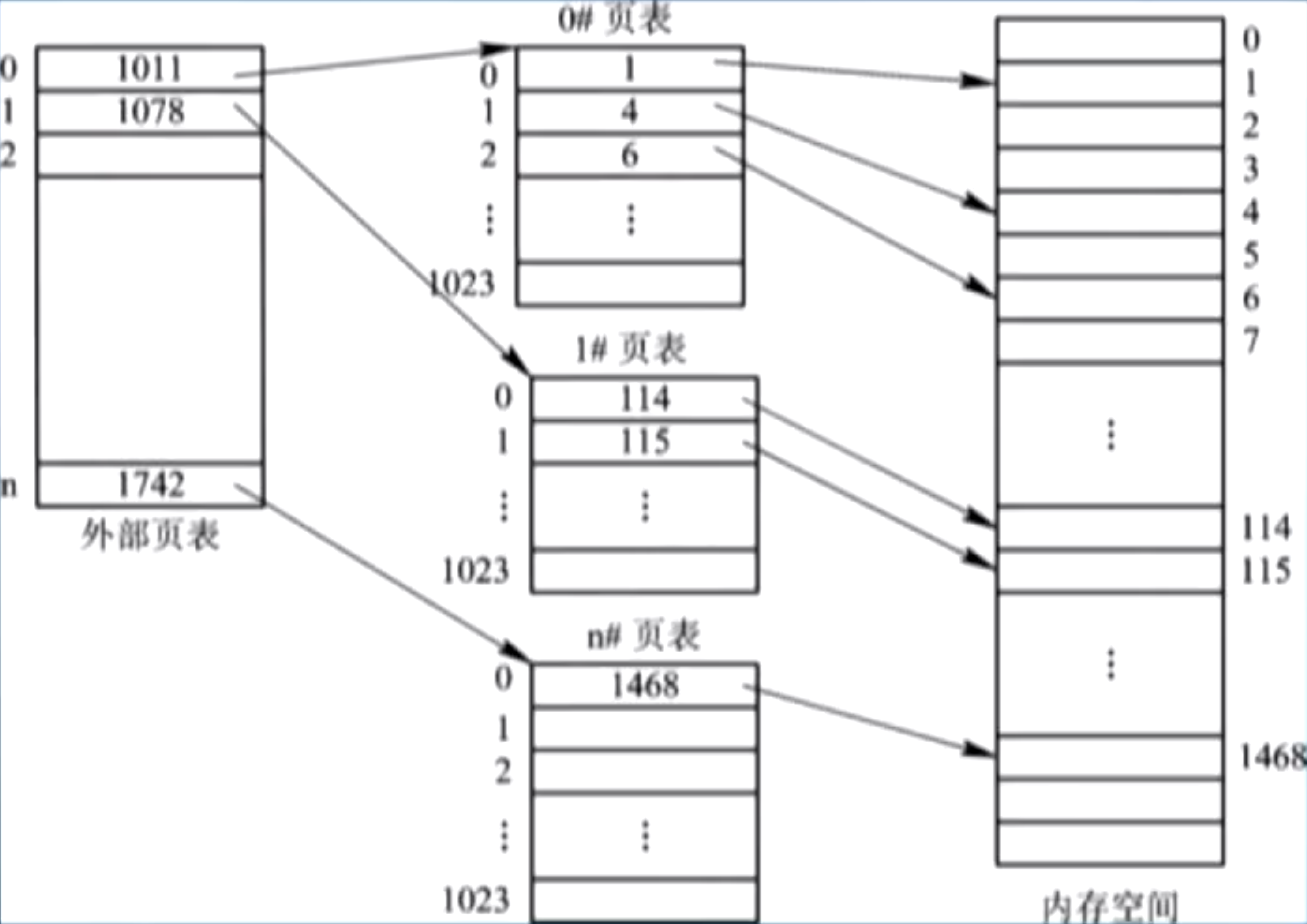
例:
的寻址:外部页表 ,在 号物理块存放的是 页表, 页表的 ,所以最终物理块为 号块,最终物理地址为 ; 从图中可以看出,每个二级页表也是离散地存放在物理块中,方便了内存管理;
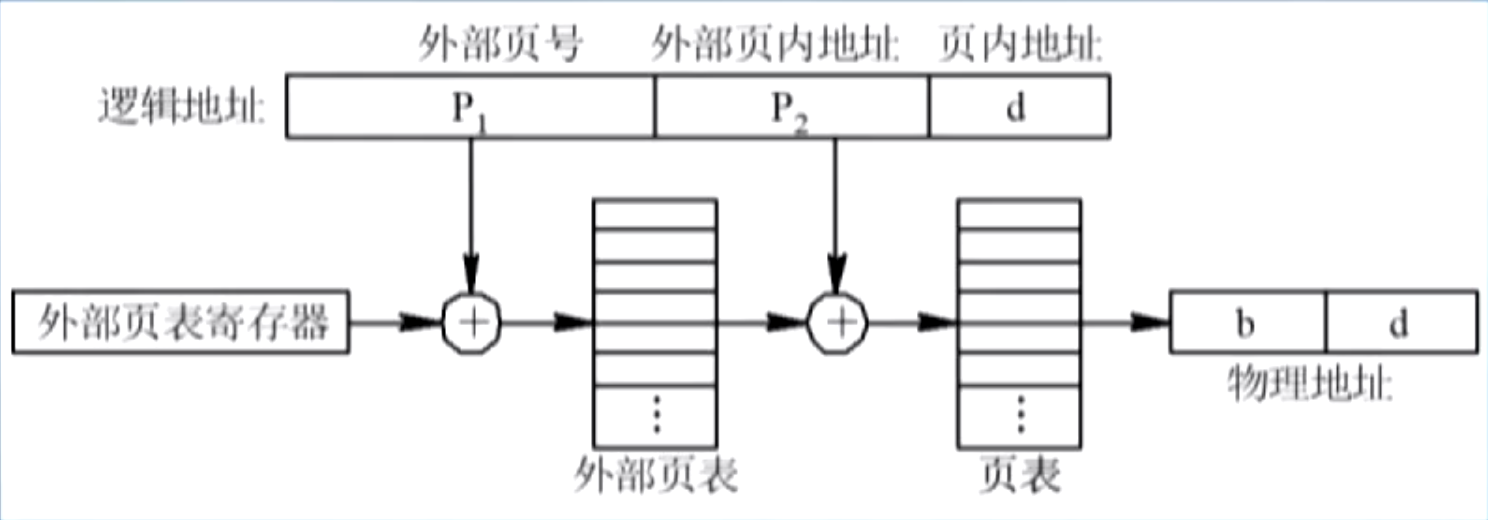
同 6.1. 基本地址变换机构,此机构也带一个外部页表寄存器(PDBR),存放外部页表的首地址和大小,和二级页表不同,外部页表是连续存放的,若外部页表的大小刚好和物理块相同,则其也存放在物理块中(如 WinXP);
PDBR 寻址方式示意
7.2. 多级页表
- OS 必须采用多级页表的原因:对于 64 位 OS,若采用两级页表,规定页面大小为 4KB,页表项仍占用 4B,则
的位数可达 42 位,对应的外层页表可能有 4096G 个页表项,需占用 16384GB 连续内存空间,显然不可能实现;
8. 段式管理
8.1. 分段存储管理的优点
方便编程:程序员将程序按照逻辑关系划分为若干个段,每个段有自己的名字,长度。程序员所使用的逻辑地址是由段名(段号)和段内偏移量组成的,这种组织方式方便了编程和模块化设计;
信息共享:主要指对程序和数据的共享,是以**信息的逻辑单位(段)**为基础,而不是页;
信息保护:同样以信息的逻辑单位(一个过程,函数或者文件)为基础;
动态增长:指程序的数据段往往会随着运行而不断增长,且对于其峰值很难预测,因此不好采取预先分配的方式进行管理;
动态链接:指 OS 运行某个程序时,不会先将其用到的所有程序都装入内存,仅主程序调用时,才动态将目标程序装入;
8.2. 分段系统的基本原理
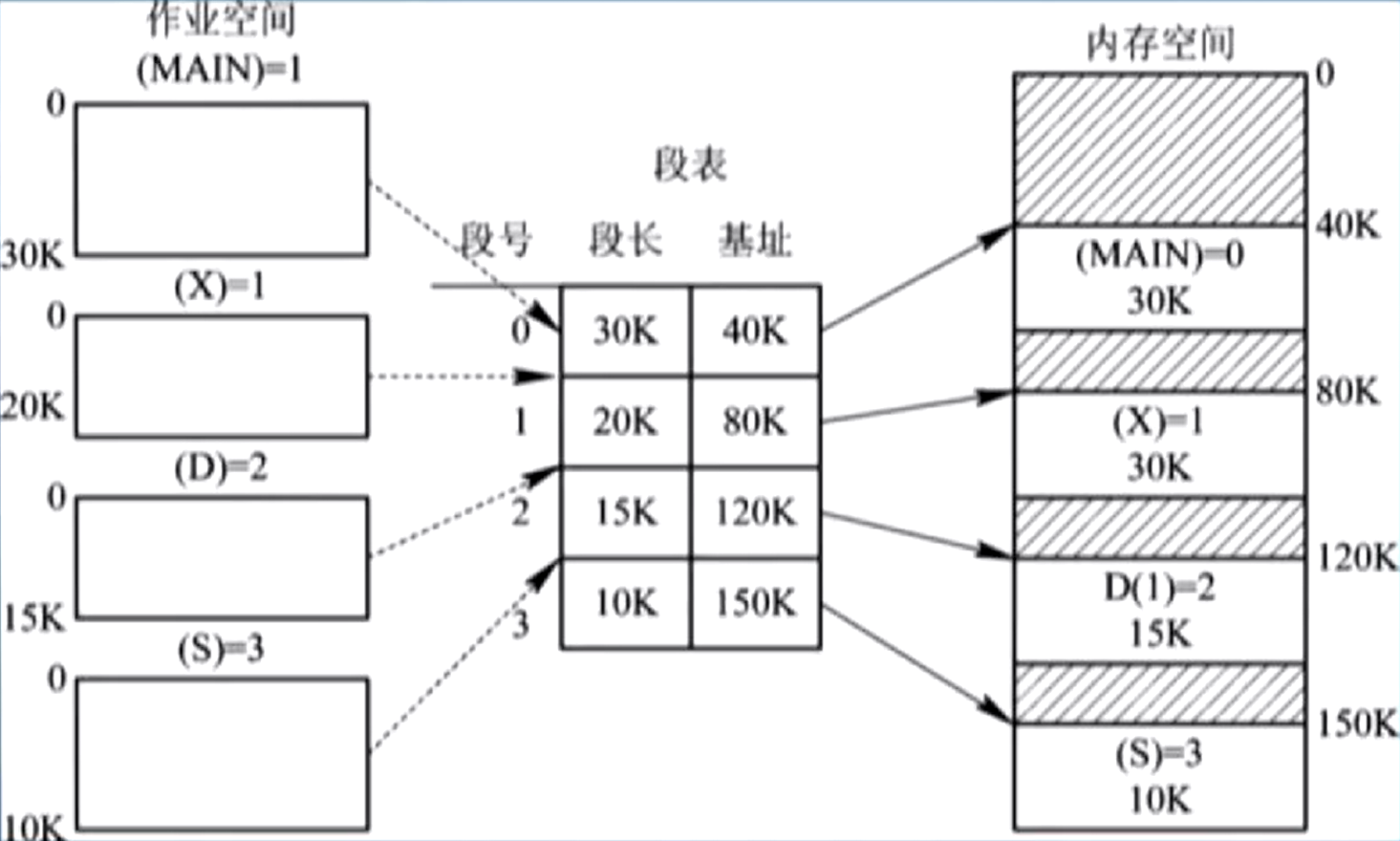
分段:将每个程序的地址空间按照逻辑意义划分为若干个段,如主程序段 MAIN,子程序段 X,数据段 D 和栈 S 等;
分段地址结构(32 位地址)

段内地址 16 位:说明每个段大小为
字节,即 64KB; 段号 16 位:最大支持 64K 个段(一般不会这么多);
段表
为每个段分配连续的存储空间(区分 2. 连续分配管理方式,每个进程 v.s. 每个段);
进程中的各个段可以分散装入内存中不同的分区中;
段表中的每个表项记录了段的首地址和长度;
示意
地址变换机构
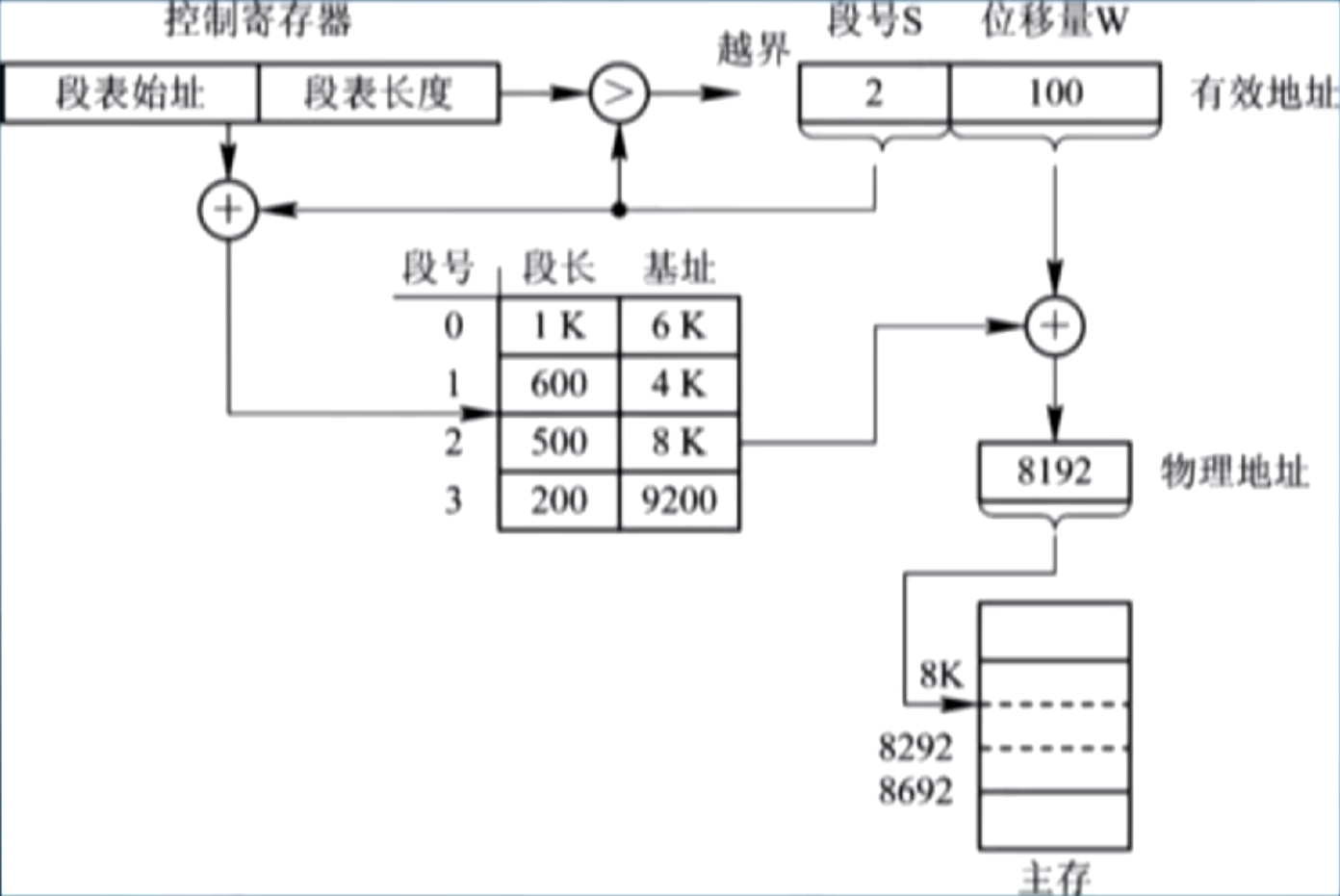
段表寄存器:存放了段表的首地址和段表长度 TL;
越界检测 1:比较给定的段号 S 和 TL,若 S
TL,则发生越界,产生越界中断 越界检测 2:比较段内地址 d 和段长 SL,若 d
SL,则产生越界中断; 注意越界检测 2 容易被忽略;
段地址变换机构也可以引入 TLB,其原理和页地址的相似;
8.3. 分页管理 v.s. 分段管理
页是信息的物理单位,分页是出于系统需要;而段是信息的逻辑单位,分段是为了方便用户需要;
页的大小固定且由系统决定,由硬件实现逻辑地址的页划分;段的长度不定,取决于程序和编译器;
分页时,程序的地址空间是一维,线性的;分段时,地址空间则是二维的(段名 + 偏移);
9. 段页式管理
9.1. 基本原理
先将程序分为若干个段,再将每个段等分为若干个页,并为每个段赋予一个段名;
段页式的逻辑地址由段号、段内页号和页内地址三个部分组成;
图示
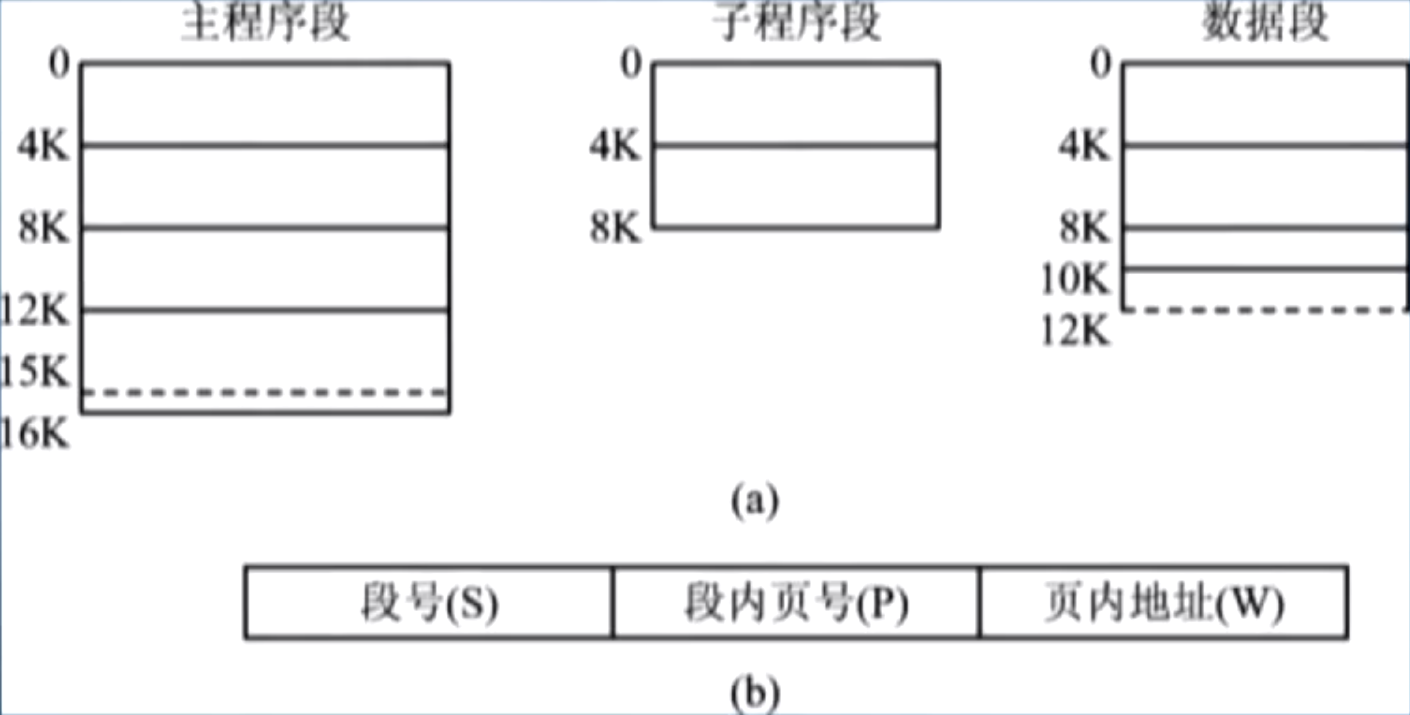
- 分析:三个段:主程序段,子程序段和数据段,页大小为 4KB;
9.2. 地址转换
与前两者不同,系统中需要同时配置段表和页表;
段表表项的内容为:此段页表的首地址和页表大小(区分 8.2. 分段系统的基本原理);
图示
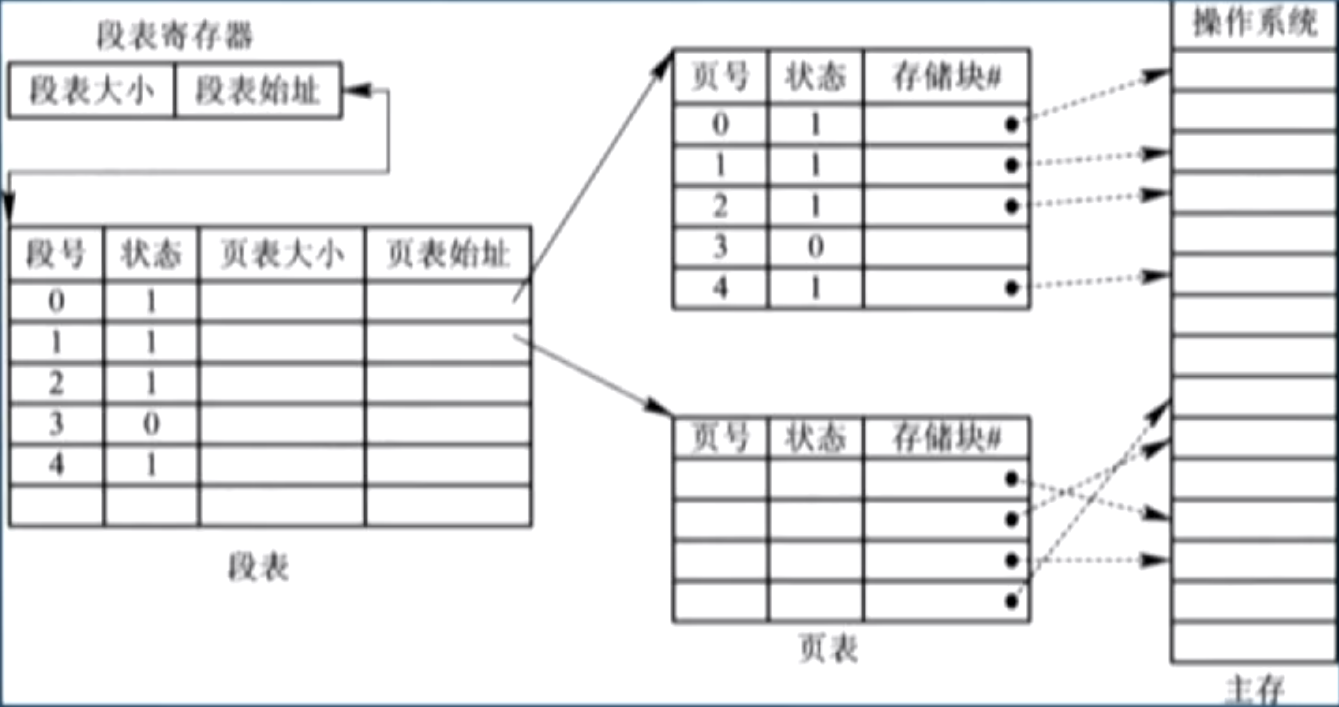
地址变换过程
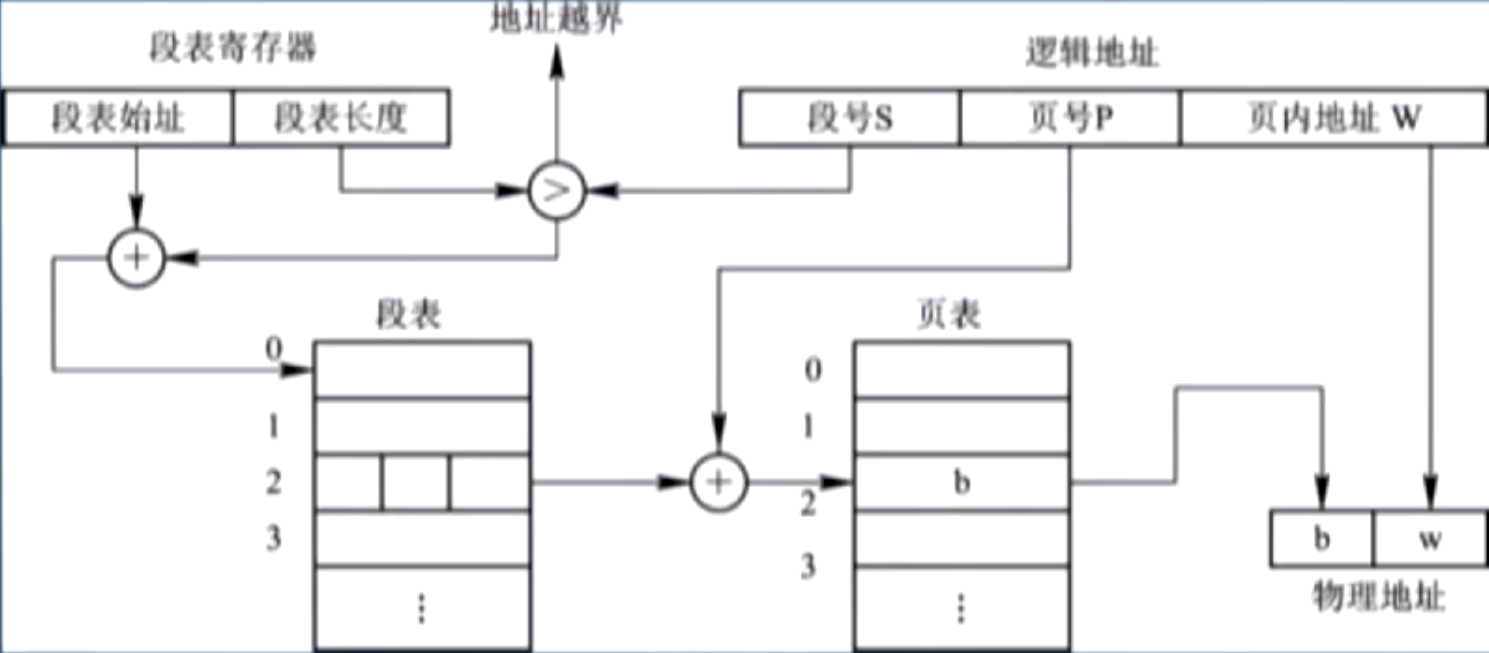
1)配置段表寄存器,存放段表首地址和长度 TL;
2)给定段号 S,和 TL 比较,进行越界检查 1;
3)段表首地址加上 S 得到页表的首地址和长度,将 P 和页表长度比较,进行越界检查 2;
4)页表首地址加上 P 得到页表项,得到物理块 b;
5)b 首地址和页内地址 W 得到最终物理地址;
上述过程一共执行了 3 次访存;